Say that you are new to research. You’ve read all the textbooks, passed all your exams, and are now beginning to perform empirical investigations. Everyone who has stepped into the lab like this is familiar with the explosion of new elements to master, things that seemed straightforward until you sat down to do them yourself. Things you never thought about. It can be daunting, but there is no other way except to learn by doing.
And what better way to make sure you are doing it right, than to try to repeat an absolutely nailed on, textbook finding? One where dozens of papers show the same effect? This is what Marcus Munafo attempted in his first study – and he failed. He couldn’t replicate the finding. Now what?
Usually, the student will conclude they did something wrong, put the study in their file drawer and try to do something else. Luckily, Marcus soon found himself at a conference where he confessed to not being able to replicate this finding. That’s when a more senior scientist told him, Oh, everybody knows that finding is crap, of course you can’t replicate that.
What does everybody knows mean? This was hidden knowledge, not part of the published record. Many other novice researchers might be wasting away their time and resources and eventually their oomph, thinking they are doing something wrong.
But (not) publishing null results is only part of the story. Let’s take a look at what happens when they become part of the published record. Here is a graph showing the citation count for 8 clinical trials using the same intervention, the use of thrombolytics to treat acute ischemic stroke (Misemer et al. 2016. Trials, 17, 473). The first conducted study was positive, showing the intervention was beneficial. It attracted a lot of attention. Of the remaining seven studies that aimed to answer the same question, two showed evidence of harm (and were aborted during data collection because of this), and four showed no effect of the intervention. And then there was one which again showed a positive effect. Can you spot the second positive study in the graph?
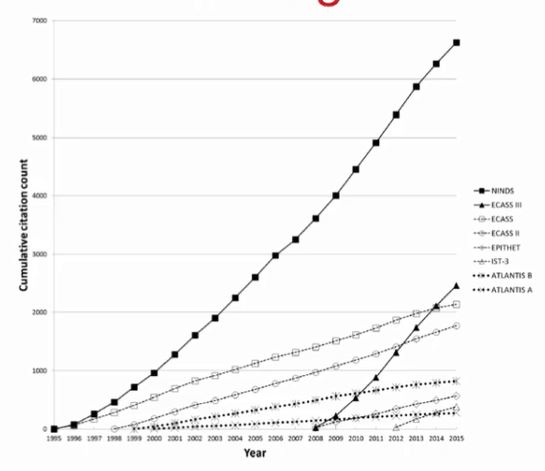
That’s right, it’s the 2008 study – the one that again got many citations. Null and negative findings, even when they are published, attract less attention. If we were to only read the studies that are well cited, we would again get a skewed picture of what research has uncovered.
The situation with untrustworthy findings is so dire that the pharmaceutical industry says they cannot sufficiently trust academic research anymore. Like in psychology, only about 30% of the academic clinical trials replicate when re-assessed.
The way we design, measure and analyse our data dramatically increases the rate of false positive findings. But the incentive structure encourages us to rely on narratives. We are told we need to have a strong story, that the data need to tell a story. But, as Marcus reminds us, we are not novelists. We are not in the business of fiction. We should be instead presenting an honest account of the scientific record – what we did, why we did it, and what we found.
Click on the video below to hear Marcus go into these and several other topics, and to hear about some solutions being tried out in the clinical literature.
(This blog post is a preview of the themes in Marcus Munafo’s talk at the Oxford Reproducibility School, held on September 27, 2017. I occasionally use my own words to describe the contents, but the presented ideas do not deviate from the talk.)
So the pharmaceutical industry cannot sufficiently trust ‘academic research’ anymore – one wonders what kind of research they do trust?
Obviously not their own as 30% replicability would be somewhat beyond Big Pharma – so wondering what other kinds of research there is?